
Introduction
Splitting variables of string type in Stata can be a shortcut to performing statistical analyses that rely on numeric rather than string variables. In this blog, we’ll show you how to take this approach, saving you plenty of time in manual recoding.
Load Data
Try the following code to load your data:
sysuse auto
describe
As you can see, these are data pertaining to automobiles:
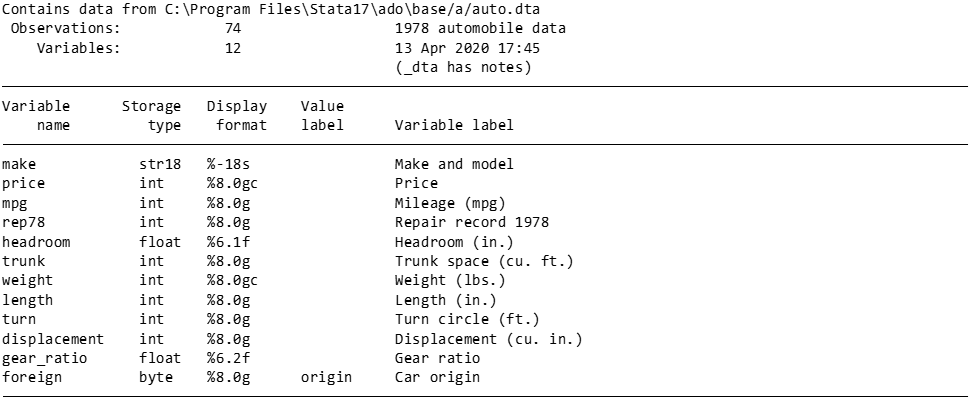
The String Variable: Make
Let’s work with the make variable, which is a string variable. You can confirm that by typing:
describe make

The storage type is str18, or string. Let’s look at the first few values of make to get a better ideas of what’s in the dataset:
list make in 1/10

Running an ANOVA
Let’s say that you want to run an ANOVA on price as a function of make. You can’t do that with a string variable, which make currently is:

Next, you might decide to use Stata’s encode function to turn the string variable of make into a numeric version of this variable. Let’s add the detail that you want to know if price varies by manufacturer (AMC, Buick, etc.). But the problem is that, if you create a new numeric version of make, it will treat each make separately. For instance, the new variable will treat AMC Concord, AMC Pacer, and AMC Spirit separately, whereas what you want is for Stata to know that each of these cars is an AMC.
Splitting the String Variable
Let’s use the split command to split the make string variable by spacing. For example, using split, the make AMC Concord will be transformed into two different string variables, one that will read “AMC” and one that will read “Concord.” Try the code:
split make
Notice that Stata automatically generates three name string variables: make1, make2, and make3. Let’s look at a cross-section of these variables to see what Stata did:
list make1 make2 make3 in 11/20
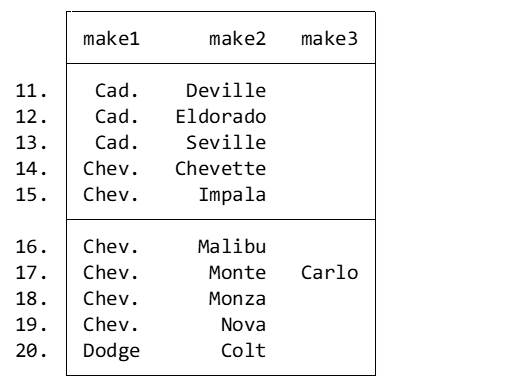
Running an ANOVA
The good news is that you can now take the string variable make1 and turn it into a numeric variable, after which you can run an ANOVA. Try:
encode make1, gen(manu)
anova price manu
The ANOVA is significant:
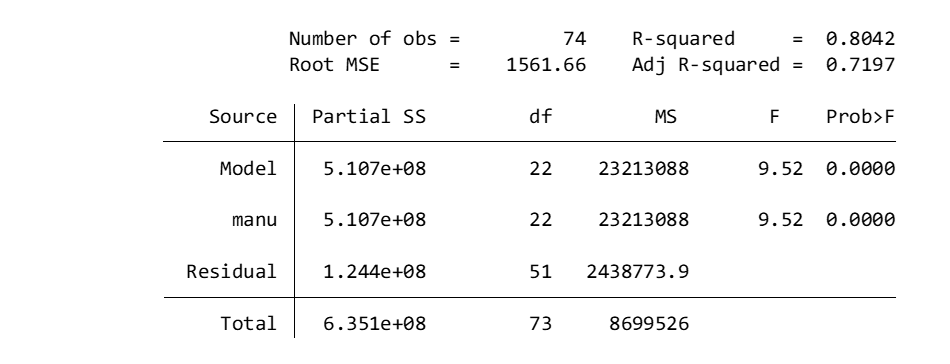
You can go further and generate some Tukey’s pairwise comparisons to get better insight into which manufacturers are more expensive:
pwmean price, over(manu) mcompare(tukey) effects
We’ll omit the readout because of the high number of comparisons, but you get the point. Starting from a string variable that didn’t support any statistical analysis, you used split to get the string into a format that let you isolate the manufacturer, encode to transform manufacturer into a numeric value, and anova / pwmean to run statistical analyses.
BridgeText can help you with all of your statistical analysis needs.




