
Introduction
Dropping unwanted rows can simplify data analysis. In this blog entry, we’ll show you how to use Stata’s drop command to eliminate unwanted rows from a given dataset. Alternatively, we’ll show you how to eliminate rows from analysis without having to drop them.
Create Data
First, we’ll create mock data, then we’ll show you how to drop rows.
set obs 30
gen subj = _n
label variable subj "Subject #"
gen q1_a = runiform(1,7)
gen q2_a = runiform(1,7)
gen q3_a = runiform(1,7)
gen q4_a = runiform(1,7)
gen q1 = round(q1_a)
gen q2 = round(q2_a)
gen q3 = round(q3_a)
gen q4 = round(q4_a)
drop q1_a q2_a q3_a q4_a
egen total = rowtotal (q1 q2 q3 q4)
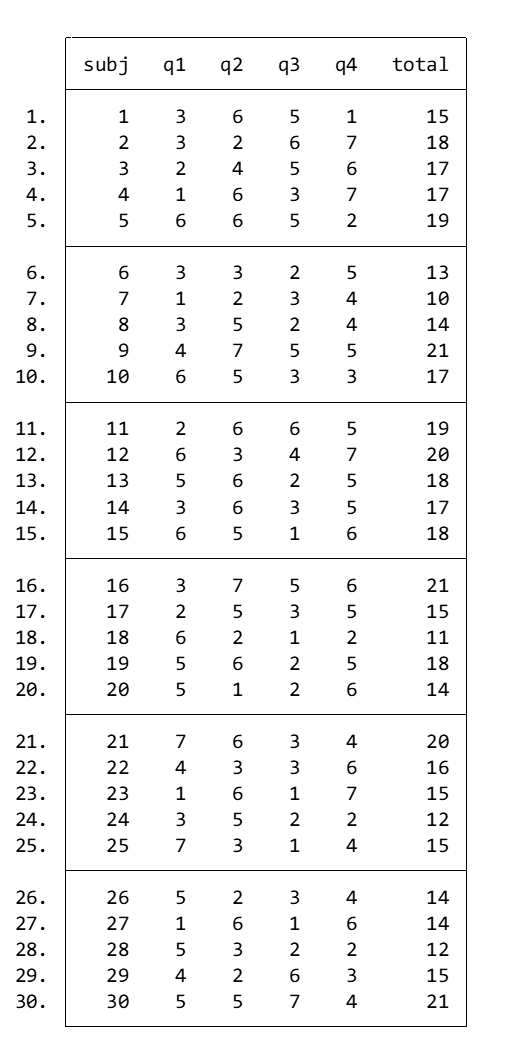
list in 1/30
Drop Unwanted Rows
Let’s say that you only wanted data from rows 1 through 20. You can use the following drop command:
drop in 21/30
This command will delete all data in rows 21 through 30.
However, if you wanted to be conservative, you could hold on to rows 21 through 30 and use the if command to focus your analysis on the relevant rows (1-20).
For example, let’s say you wanted to run a one-sample t-test in Stata to see if the total differs significantly from 16, and you are only concerned about rows 1-20. Note that rows 1-20 correspond to data from subjects 1-20. Therefore, you could try:
ttest total = 16 if subj < 21
Notice that, when you apply the if command to delimit your analysis to subjects 1-20 (and, therefore, rows 1-20), Stata focuses on the relevant portion of the dataset automatically:

If you genuinely have no use for rows 21-30, though, use the drop command and confirm that the rows have been deleted:
drop in 21/30
edit
BridgeText can help you with all of your statistical analysis needs.




