
Introduction
The chi square statistic and its underlying p value are most often calculated in order to determine whether some observed distribution is normal. In this post, we’ll show you how to run and interpret a chi square analysis in Stata.
Load the Dataset
Let’s load Stata’s prebuilt auto dataset using the following code:
sysuse auto
Two of the variables in the dataset are as follows:
rep78: How many times the car was repaired
foreign: Whether or not the car is foreign
Create a Table and Hypothesis
Try the following code to visualize your data before running the Chi square:
tab2 rep78 foreign
You get the following:

You want to know whether there is an effect on the manufacturing location of a car (domestic vs. foreign) on the number of times it was repaired.
Run and Interpret the Chi Square
Now you can enter the following code:
tab rep78 foreign, chi2
You get the following:
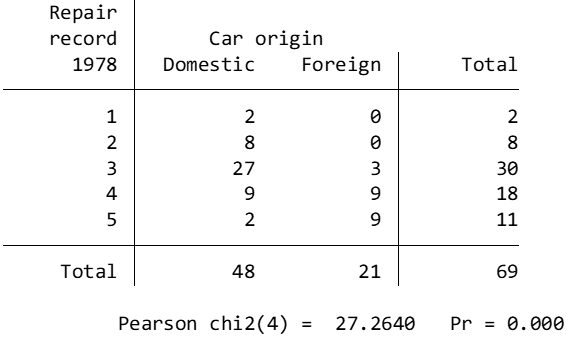
If the p value for the Chi square is less than .05, you could justifiably conclude that there is some relationship between the manufacturing location of a car and the number of times it was repaired. Here, the p value is < .001, so there is indeed a relationship between the manufacturing location of a car and the number of times it was repaired.
BridgeText can help you with all of your statistical analysis needs.




