
Introduction
Sometimes, when conducting a statistical procedure, you need to know how to be able to integrate categorical (factor) variables into your analysis. In this blog, we’ll offer some points on how to use categorical variables by applying the i. prefix in Stata.
Load Data
Load a dataset by entering the following code into Stata’s command line:
use https://www.stata-press.com/data/r17/censusfv.dta
describe
Here are details on this dataset:

Run a Regression and Add Factor Variables
Looking at the dataset, you note that there are four census regions:
tab region
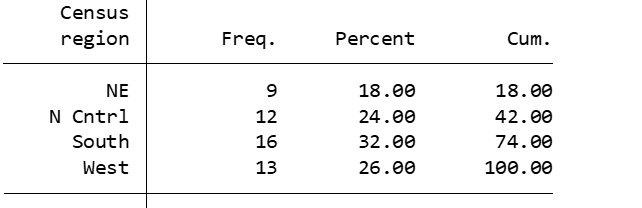
Note that Stata has already assigned the following numeric variables to each region:
NE: 1
N Cntrl: 2
South: 3
West: 4
Let’s check on the relationship between divorces per 100,000 and region, using the following code:
regress divorcert i.region
Here are the results of your regression model:
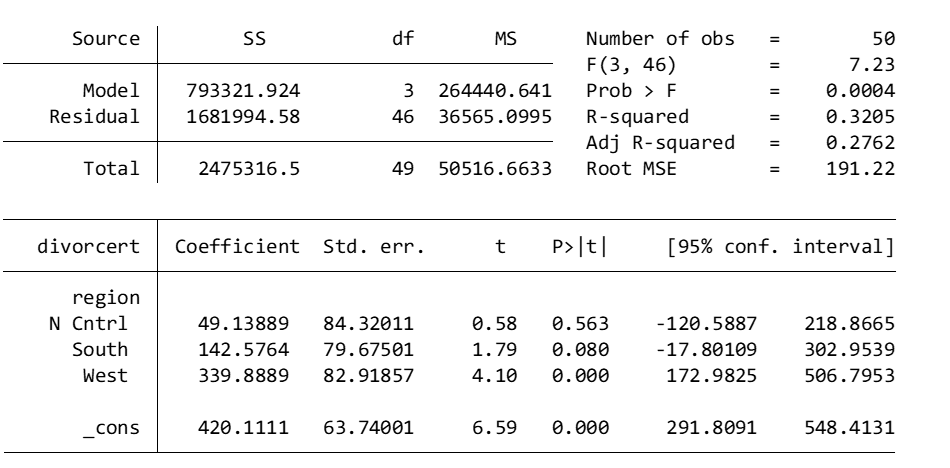
Although there are four regions in the dataset, there are only three regions in the regression model. The reason for this is that Stata automatically treats region 1 (NE) as the base or comparator value. Thus, using p < .10, we can conclude that:
The South has 142.58 more divorces / 100,000 than the NE
The West has 339.89 more divorces / 100,000 than the NE
Here, the use of the i.prefix allows us to compare each value of the categorical value to the selected base value. Of course, you might want a different comparison. For example, you might be interested in making the West region your base and creating regression equations accordingly. Because West = 4 in Stata’s coding, try the following code:
regress divorcert b4.region
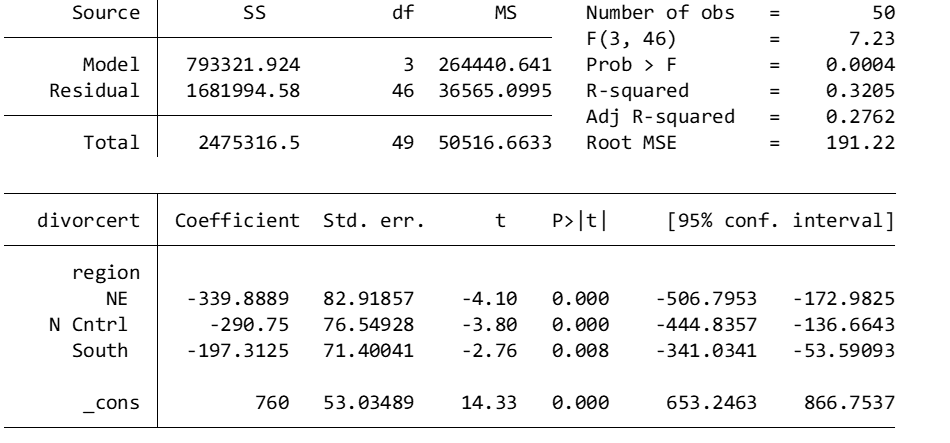
Notice that your comparisons are now to the West region. We can conclude that:
The NE has 339.89 fewer divorces than the West
N Cntrl has 290.75 fewer divorces than the West
The South has 197.31 fewer divorces than the West
BridgeText can help you with all of your statistical analysis needs.




